Key Concepts
データ構造(Data Structure)
データ構造は、エージェントが使用する構造化データの設計図として機能します。
各データフィールド(列)、そのタイプ、必須かどうかを定義し、データの一貫性を確保するとともに、エージェントが情報を高い信頼性で処理できるようにします。
データ整合性: 事前にデータ形式(Type)を定義することで、データ保存・取得時にエージェントが一貫したルールに従うことを保証します。
処理効率: 定義されたスキーマに基づきデータ処理ロジックを体系的に整理でき、複雑なビジネスロジックを効率的に実装できます。
再利用性と拡張性: 一度定義したデータ構造は複数の構造化データストレージで再利用でき、ワークフロー開発と管理の効率を高めます。
データ構造の作成と管理
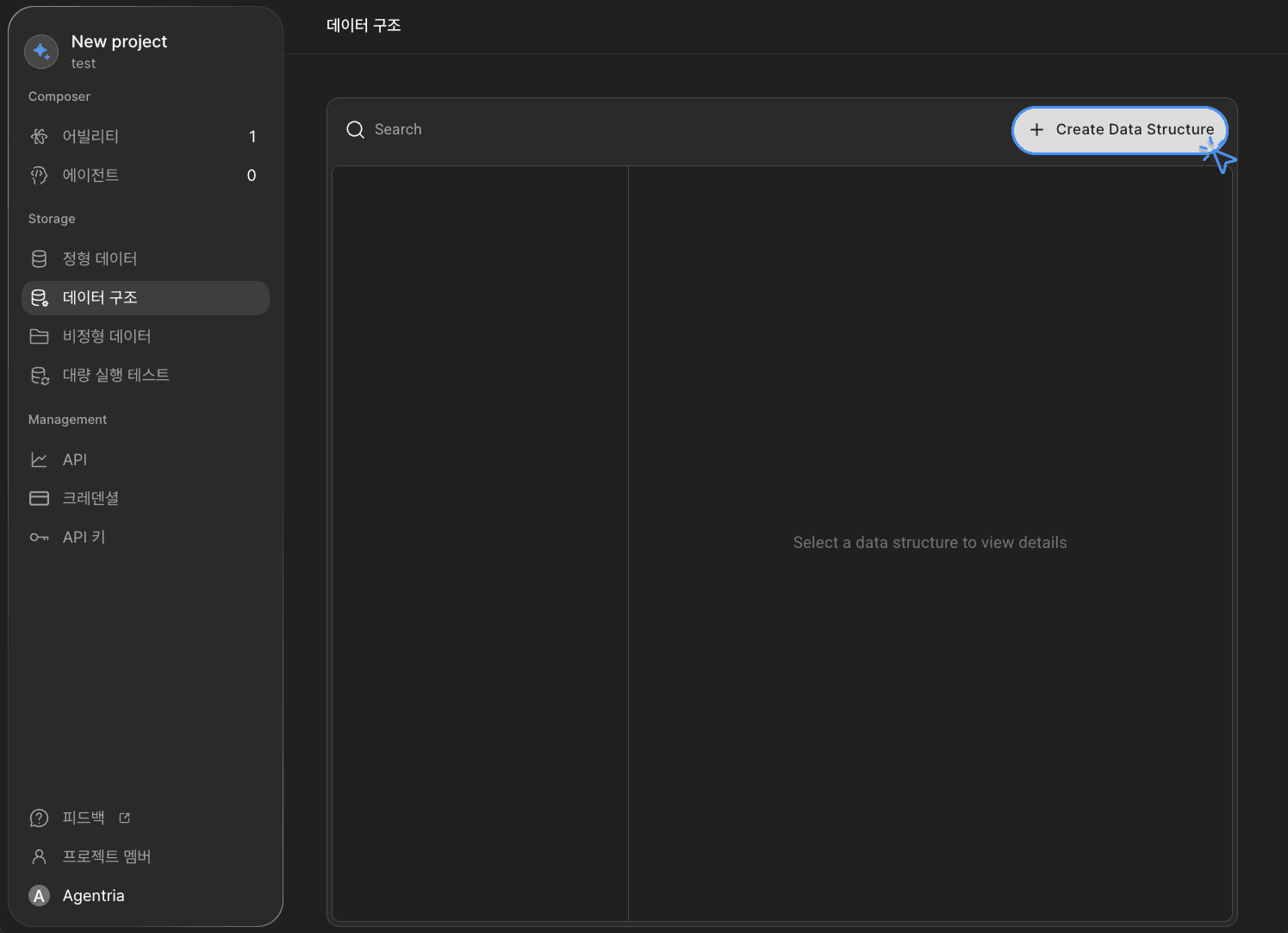
データ構造を作成: 右上の
+Create Data Structureボタンをクリックして新しい構造を作成します。

フィールドを定義・編集: 既存または新規作成した構造を選択し、フィールドを追加・修正した後、
+Saveをクリックして変更を保存します。Type: フィールドのデータタイプ(例:Text、Number、Date など)を指定します。
Name: フィールドの一意な内部名を割り当てます。
Required: このフィールドがデータ入力時に必須かどうかを決定します。
Indexing: 検索性能を高めるため、このフィールドをインデックスとして使用するか選択します。
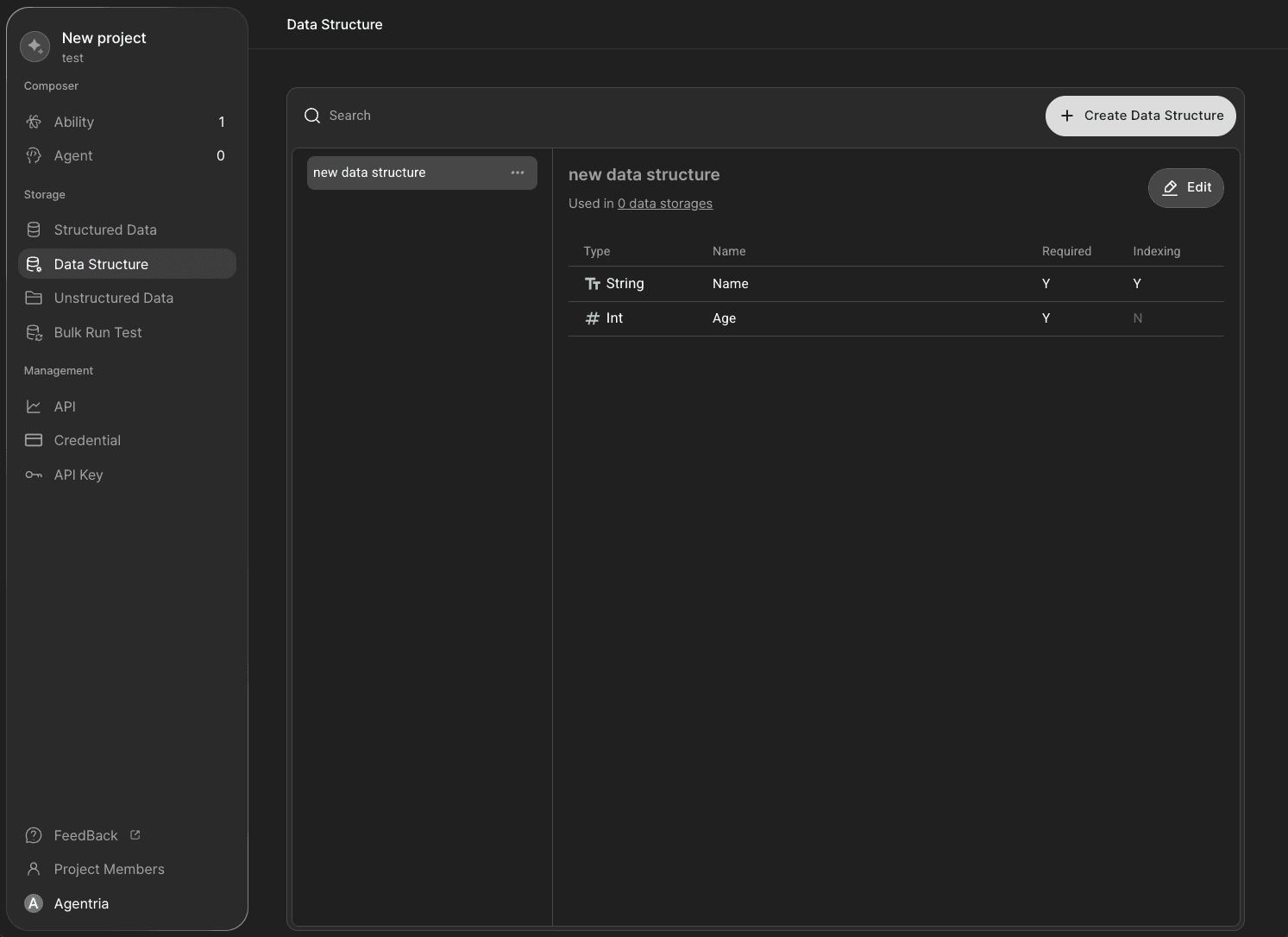
完成した構造には、現在使用されているストレージ数(例:Used in 0 data storages)が表示されます。
構造化データストレージを作成する際、この構造を選択して実際のデータ保存用スキーマとして使用できます。
Editボタンをクリックして、いつでも編集モードに入れます。